-
Tensorflow RNN 을 활용한 sarcasm분류 모델AI/Tensorflow 2020. 12. 24. 17:02728x90
순환 신경망 (Recurrent Neural Network) RNN 을 활용한 텍스트 분류 (Text Classification)
RNN이란?
입력과 출력을 시퀀스 단위로 처리하는 모델.
번역기를 생각해보면 입력은 번역하고자 하는 문장. 즉, 단어 시퀀스.
출력에 해당되는 번역된 문장 또한 단어 시퀀스.
이러한 시퀀스들을 처리하기 위해 고안된 모델들을 시퀀스 모델이라고 한다.
그 중에서도 RNN은 딥 러닝에 있어 가장 기본적인 시퀀스 모델이다.
1. 순환 신경망(Recurrent Neural Network, RNN)
앞서 배운 신경망들은 전부 은닉층에서 활성화 함수를 지난 값은 오직 출력층 방향으로만 향했습니다. 이와 같은 신경망들을 피드 포워드 신경망(Feed Forward Neural Network)이라고 합니다. 그런데 그렇지 않은 신경망들이 있습니다. RNN(Recurrent Neural Network) 또한 그 중 하나입니다. RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징을 갖고있습니다.

이를 그림으로 표현하면 위와 같습니다. xx는 입력층의 입력 벡터, yy는 출력층의 출력 벡터입니다. 실제로는 편향 bb도 입력으로 존재할 수 있지만 앞으로의 그림에서는 생략합니다. RNN에서 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드를 셀(cell)이라고 합니다. 이 셀은 이전의 값을 기억하려고 하는 일종의 메모리 역할을 수행하므로 이를 메모리 셀 또는 RNN 셀이라고 표현합니다.
은닉층의 메모리 셀은 각각의 시점(time step)에서 바로 이전 시점에서의 은닉층의 메모리 셀에서 나온 값을 자신의 입력으로 사용하는 재귀적 활동을 하고 있습니다. 앞으로는 현재 시점을 변수 t로 표현하겠습니다. 이는 현재 시점 t에서의 메모리 셀이 갖고있는 값은 과거의 메모리 셀들의 값에 영향을 받은 것임을 의미합니다. 그렇다면 메모리 셀이 갖고 있는 이 값은 뭐라고 부를까요?
메모리 셀이 출력층 방향으로 또는 다음 시점 t+1의 자신에게 보내는 값을 은닉 상태(hidden state)라고 합니다. 다시 말해 t 시점의 메모리 셀은 t-1 시점의 메모리 셀이 보낸 은닉 상태값을 t 시점의 은닉 상태 계산을 위한 입력값으로 사용합니다.

RNN을 표현할 때는 일반적으로 위의 그림에서 좌측과 같이 화살표로 사이클을 그려서 재귀 형태로 표현하기도 하지만, 우측과 같이 사이클을 그리는 화살표 대신 여러 시점으로 펼쳐서 표현하기도 합니다. 두 그림은 동일한 그림으로 단지 사이클을 그리는 화살표를 사용하여 표현하였느냐, 시점의 흐름에 따라서 표현하였느냐의 차이일 뿐 둘 다 동일한 RNN을 표현하고 있습니다.
피드 포워드 신경망에서는 뉴런이라는 단위를 사용했지만, RNN에서는 뉴런이라는 단위보다는 입력층과 출력층에서는 각각 입력 벡터와 출력 벡터, 은닉층에서는 은닉 상태라는 표현을 주로 사용합니다. 그래서 사실 위의 그림에서 회색과 초록색으로 표현한 각 네모들은 기본적으로 벡터 단위를 가정하고 있습니다. 피드 포워드 신경망과의 차이를 비교하기 위해서 RNN을 뉴런 단위로 시각화해보겠습니다.

위의 그림은 입력 벡터의 차원이 4, 은닉 상태의 크기가 2, 출력층의 출력 벡터의 차원이 2인 RNN이 시점이 2일 때의 모습을 보여줍니다. 다시 말해 뉴런 단위로 해석하면 입력층의 뉴런 수는 4, 은닉층의 뉴런 수는 2, 출력층의 뉴런 수는 2입니다.
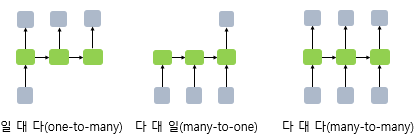
RNN은 입력과 출력의 길이를 다르게 설계 할 수 있으므로 다양한 용도로 사용할 수 있습니다. 위 그림은 입력과 출력의 길이에 따라서 달라지는 RNN의 다양한 형태를 보여줍니다. 위 구조가 자연어 처리에서 어떻게 사용될 수 있는지 예를 들어봅시다. RNN 셀의 각 시점 별 입, 출력의 단위는 사용자가 정의하기 나름이지만 가장 보편적인 단위는 '단어 벡터'입니다.
예를 들어 하나의 입력에 대해서 여러개의 출력(one-to-many)의 모델은 하나의 이미지 입력에 대해서 사진의 제목을 출력하는 이미지 캡셔닝(Image Captioning) 작업에 사용할 수 있습니다. 사진의 제목은 단어들의 나열이므로 시퀀스 출력입니다.

또한 단어 시퀀스에 대해서 하나의 출력(many-to-one)을 하는 모델은 입력 문서가 긍정적인지 부정적인지를 판별하는 감성 분류(sentiment classification), 또는 메일이 정상 메일인지 스팸 메일인지 판별하는 스팸 메일 분류(spam detection)에 사용할 수 있습니다. 위 그림은 RNN으로 스팸 메일을 분류할 때의 아키텍처를 보여줍니다. 이러한 예제들은 11챕터에서 배우는 텍스트 분류에서 배웁니다.

다 대 다(many-to-many)의 모델의 경우에는 입력 문장으로 부터 대답 문장을 출력하는 챗봇과 입력 문장으로부터 번역된 문장을 출력하는 번역기, 또는 13챕터에서 배우는 개체명 인식이나 품사 태깅과 같은 작업 또한 속합니다. 위 그림은 개체명 인식을 수행할 때의 RNN 아키텍처를 보여줍니다.
이제 RNN에 대한 수식을 정의해보겠습니다.

현재 시점 t에서의 은닉 상태값을 htht라고 정의하겠습니다. 은닉층의 메모리 셀은 htht를 계산하기 위해서 총 두 개의 가중치를 갖게 됩니다. 하나는 입력층에서 입력값을 위한 가중치 WxWx이고, 하나는 이전 시점 t-1의 은닉 상태값인 ht−1ht−1을 위한 가중치 WhWh입니다.
이를 식으로 표현하면 다음과 같습니다.
은닉층 : ht=tanh(Wxxt+Whht−1+b)ht=tanh(Wxxt+Whht−1+b)
출력층 : yt=f(Wyht+b)yt=f(Wyht+b)
단, ff는 비선형 활성화 함수 중 하나.RNN의 은닉층 연산을 벡터와 행렬 연산으로 이해할 수 있습니다. 자연어 처리에서 RNN의 입력 xtxt는 대부분의 경우에서 단어 벡터로 간주할 수 있는데, 단어 벡터의 차원을 dd라고 하고, 은닉 상태의 크기를 DhDh라고 하였을 때 각 벡터와 행렬의 크기는 다음과 같습니다.
xtxt : (d×1)(d×1)
WxWx : (Dh×d)(Dh×d)
WhWh : (Dh×Dh)(Dh×Dh)
ht−1ht−1 : (Dh×1)(Dh×1)
bb : (Dh×1)(Dh×1)배치 크기가 1이고, dd와 DhDh 두 값 모두를 4로 가정하였을 때, RNN의 은닉층 연산을 그림으로 표현하면 아래와 같습니다.

이때 htht를 계산하기 위한 활성화 함수로는 주로 하이퍼볼릭탄젠트 함수(tanh)가 사용되지만, ReLU로 바꿔 사용하는 시도도 있습니다.
위의 식에서 각각의 가중치 WxWx, WhWh, WyWy의 값은 모든 시점에서 값을 동일하게 공유합니다. 만약, 은닉층이 2개 이상일 경우에는 은닉층 2개의 가중치는 서로 다릅니다.
출력층은 결과값인 ytyt를 계산하기 위한 활성화 함수로는 상황에 따라 다를텐데, 예를 들어서 이진 분류를 해야하는 경우라면 시그모이드 함수를 사용할 수 있고 다양한 카테고리 중에서 선택해야하는 문제라면 소프트맥스 함수를 사용하게 될 것입니다.
RNN 출처 -1) 순환 신경망(Recurrent Neural Network, RNN) - 딥 러닝을 이용한 자연어 처리 입문 (wikidocs.net)
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
바닐라 RNN의 한계 개선 - LSTM
2) 장단기 메모리(Long Short-Term Memory, LSTM) - 딥 러닝을 이용한 자연어 처리 입문 (wikidocs.net)
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
#import import json import tensorflow as tf import numpy as np import urllib from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional, Flatten from tensorflow.keras.models import Sequential from tensorflow.keras.callbacks import ModelCheckpoint #Load Dataset url = 'https://storage.googleapis.com/download.tensorflow.org/data/sarcasm.json' urllib.request.urlretrieve(url, 'sarcasm.json') #Json file load with open('sarcasm.json') as f: datas = json.load(f) #datas 5개 출력 #article_link: 뉴스 기사 URL #headline: 뉴스기사의 제목 #is_sarcastic: 비꼬는 기사 여부 (비꼼: 1, 일반: 0) datas[:5] #전처리: 데이터셋 구성(sentences, labels) #X (Feature): sentences #Y (Label): label #빈 list를 생성합니다. (sentences, labels) sentences = [] labels = [] for data in datas: sentences.append(data['headline']) labels.append(data['is_sarcastic']) #문장 5개를 출력 sentences[:5] labels[:5] #Train / Validation Set 분리 #20,000개를 기준으로 데이터셋을 분리합니다. training_size = 20000 train_sentences = sentences[:training_size] train_labels = labels[:training_size] validation_sentences = sentences[training_size:] validation_labels = labels[training_size:] #전처리 Step 1. Tokenizer 정의 #단어의 토큰화를 진행합니다. #num_words: 단어 max 사이즈를 지정합니다. 가장 빈도수가 높은 단어부터 저장합니다. vocab_size으로 지정함. #oov_token: 단어 토큰에 없는 단어를 어떻게 표기할 것인지 지정해줍니다. vocab_size = 1000 oov_tok = '<OOV>' tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok) #전처리 Step 2. Tokenizer로 학습시킬 문장에 대한 토큰화 진행 #fit_on_texts로 학습할 문장에 대하여 토큰화를 진행합니다. tokenizer.fit_on_texts(train_sentences) for key, value in tokenizer.word_index.items(): print('{} \t======>\t {}'.format(key, value)) if value == 25: break #토큰화된 단어 사전의 갯수 25637나옴 len(tokenizer.word_index) #단어사전은 dictionary 형태로 되어 있습니다. #즉, 단어를 key로 입력하면 값을 return 합니다. word_index = tokenizer.word_index print(word_index['trump']) print(word_index['hello']) print(word_index['<OOV>']) #전처리 Step 3. 문장(sentences)을 토큰으로 변경 (치환) #texts_to_sequences: 문장을 숫자로 치환 합니다. Train Set, Valid Set 모두 별도로 적용해주어야 합니다. train_sequences = tokenizer.texts_to_sequences(train_sentences) validation_sequences = tokenizer.texts_to_sequences(validation_sentences) #변환된 Sequences 5개 확인 print(train_sequences[:5]) #변환 과정에서 ''로 변환된 단어 확인 #빈도수로 지정한 num_words=1000 에 의거하여, 빈도수가 1000번째보다 떨어지는 단어는 자동으로 1로 치환됩니다. #1은 '' 입니다. (Out of Vocab) print(train_sentences[4]) print(word_index['j'], word_index['k'], word_index['rowling'], word_index['wishes'], word_index['snape'], word_index['happy']) train_sequences[4] #전처리 Step 4. 시퀀스의 길이를 맞춰주기 #3가지 옵션을 입력해 줍니다. #maxlen: 최대 문장 길이를 정의합니다. 최대 문장길이보다 길면, 잘라냅니다. #truncating: 문장의 길이가 maxlen보다 길 때 앞을 자를지 뒤를 자를지 정의합니다. #padding: 문장의 길이가 maxlen보다 짧을 때 채워줄 값을 앞을 채울지, 뒤를 채울지 정의합니다. #한 문장의 최대 단어 숫자 max_length = 120 #잘라낼 문장의 위치 trunc_type = 'post' #채워줄 문장의 위치, 앞부분을 채워주려면 'pre'를 쓰면 된다. padding_type = 'post' train_padded = pad_sequences(train_sequences, maxlen=max_length, truncating=trunc_type, padding=padding_type) validation_padded = pad_sequences(validation_sequences, maxlen=max_length, truncating=trunc_type, padding=padding_type) #변환된 후 shape 확인 train_padded.shape #전처리 Step 5. label 값을 numpy array로 변환 #model이 list type은 받아들이지 못하므로, numpy array로 변환합니다. train_labels = np.array(train_labels) validation_labels = np.array(validation_labels) #Embedding Layer #고차원을 저차원으로 축소시켜주는 역할을 합니다. #one-hot encoding을 진행했을 때, 1000차원으로 표현되는 단어들을 16차원으로 줄여주는 겁니다. 그렇게 해서 sparsity문제를 해소하도록 유도합니다. embedding_dim = 16 #변환 전 sample = np.array(train_padded[0]) print(sample) #변환 후 x = Embedding(vocab_size, embedding_dim, input_length=max_length) print(x(sample)[0]) #모델 정의 (Sequential) model = Sequential([ Embedding(vocab_size, embedding_dim, input_length=max_length), Bidirectional(LSTM(64, return_sequences=True)), #many to many , LSTM 층을 겹쳐서 사용하면 return_sequences=TRUE 를 반드시 줘야한다. Bidirectional(LSTM(64)), #many to one Dense(32, activation='relu'), Dense(16, activation='relu'), Dense(1, activation='sigmoid') ]) #요약 확인 model.summary() #컴파일 (compile) #optimizer는 가장 최적화가 잘되는 알고리즘인 'adam'을 사용합니다. #loss는 이진 분류이기 때문에 binary_crossentropy를 사용합니다. model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc']) #ModelCheckPoint 생성 checkpoint_path = "my_checkpoint.ckpt" checkpoint = ModelCheckpoint(checkpoint_path, save_weights_only=True, save_best_only=True, monitor='val_loss', verbose=1) #학습 fit epochs = 10 history = model.fit(train_padded, train_labels, validation_data=(validation_padded, validation_labels), callbacks=[checkpoint], epochs=epochs) #학습 완료 후 Load Weights (ModelCheckpoint) #학습이 완료된 후에는 반드시 load_weights를 해주어야 합니다. #그렇지 않으면, 열심히 ModelCheckpoint를 만든 의미가 없습니다. model.load_weights(checkpoint_path) #학습 오차에 대한 시각화 import matplotlib.pyplot as plt plt.figure(figsize=(12, 9)) plt.plot(np.arange(1, epochs+1), history.history['loss']) plt.plot(np.arange(1, epochs+1), history.history['val_loss']) plt.title('Loss / Val Loss', fontsize=20) plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend(['loss', 'val_loss'], fontsize=15) plt.show() plt.figure(figsize=(12, 9)) plt.plot(np.arange(1, epochs+1), history.history['acc']) plt.plot(np.arange(1, epochs+1), history.history['val_acc']) plt.title('Acc / Val Acc', fontsize=20) plt.xlabel('Epochs') plt.ylabel('Acc') plt.legend(['acc', 'val_acc'], fontsize=15) plt.show()728x90반응형'AI > Tensorflow' 카테고리의 다른 글
Tensorflow Certification 합격 (0) 2021.01.04 Tensorflow windowed dataset 활용법 (0) 2020.12.24 Tensorflow 과대적합과 과소적합 (0) 2020.12.23 Tensorflow 자격증 1번 문제 모델 (0) 2020.12.23 Tensorflow Dense Layer (0) 2020.12.23