AI/ML.NET
ML.NET MSSQL 연동 [5]
Urong
2020. 12. 1. 18:04
728x90
ML.NET 을 건드린지 1주가 지났는데 아직 자동화 밖에 쓰질 못하겠다.
그래서 자동화로 생성된 코드들을 보기로 했다.
시나리오를 선택하고 환경 선택하고 데이터를 선택하고 학습을 하면
가장 정확도가 높은 알고리즘을 찾아준다.
학습시간이 길 수록 정확도가 높아지지만 적은 데이터를 무작정 길게 학습한다고해서 더욱더 좋아지지는 않는다.
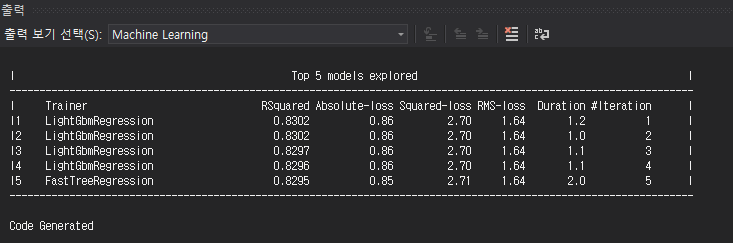
LightGbmRegression이 제일 높은 정확도를 가진것으로 결과가 나왔다.
이 상태로 코드에서 프로젝트추가를 하면

이렇게 코드가 추가되고 샘프로 코드가 주어진다.

그럼 생성된 프로젝트로 들어가보자.
ConsoleApp에 들어가보면 ModelBuilder 클래스가 있다.
여기에서 학습시킨 후에 선택된 알고리즘 LightGbmRegression를 사용해서 모델을 생성하는 코드들을 확인 할 수 있다.
알고리즘에 대한 옵션도 들어가 있고 생성된 모델의 저장위치도 지정된다.
알고리즘이 바뀌도록 데이터를 바꿔가면서 해봤는데 생성되는 코드가 확실하게 다르다.
public static void CreateModel()
{
// 데이터를 읽어서
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<ModelInput>(
path: TRAIN_DATA_FILEPATH,
hasHeader: true,
separatorChar: '\t',
allowQuoting: true,
allowSparse: false);
// 학습 pipeline 을 만들고
IEstimator<ITransformer> trainingPipeline = BuildTrainingPipeline(mlContext);
// 모델을 학습시키고
ITransformer mlModel = TrainModel(mlContext, trainingDataView, trainingPipeline);
// Evaluate quality of Model
Evaluate(mlContext, trainingDataView, trainingPipeline);
// 모델을 저장한다.
SaveModel(mlContext, mlModel, MODEL_FILEPATH, trainingDataView.Schema);
}
//pipeline을 만드는데 여기에서 알고리즘을 선택한다.
public static IEstimator<ITransformer> BuildTrainingPipeline(MLContext mlContext)
{
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Concatenate("Features", new[] { "A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M" });
// Set the training algorithm
//LightGbmRegression이 선택되어있는걸 볼 수 있다.
var trainer = mlContext.Regression.Trainers.LightGbm(new LightGbmRegressionTrainer.Options() { NumberOfIterations = 100, LearningRate = 0.05942692f, NumberOfLeaves = 70, MinimumExampleCountPerLeaf = 20, UseCategoricalSplit = false, HandleMissingValue = true, UseZeroAsMissingValue = true, MinimumExampleCountPerGroup = 50, MaximumCategoricalSplitPointCount = 16, CategoricalSmoothing = 1, L2CategoricalRegularization = 10, Booster = new GradientBooster.Options() { L2Regularization = 0.5, L1Regularization = 0 }, LabelColumnName = "도막두께", FeatureColumnName = "Features" });
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
}여기에서 데이터를 불러와서 모델을 만들고 학습시키는 과정을 거치고
Model 프로젝트로 들어가면 ConsumeMedel 클래스에서 생성된 모델에 값을 입력하고 예측값을 리턴받는다.
public class ConsumeModel
{
private static Lazy<PredictionEngine<ModelInput, ModelOutput>> PredictionEngine = new Lazy<PredictionEngine<ModelInput, ModelOutput>>(CreatePredictionEngine);
// For more info on consuming ML.NET models, visit https://aka.ms/mlnet-consume
// Method for consuming model in your app
public static ModelOutput Predict(ModelInput input)
{
ModelOutput result = PredictionEngine.Value.Predict(input);
return result;
}
public static PredictionEngine<ModelInput, ModelOutput> CreatePredictionEngine()
{
// Create new MLContext
MLContext mlContext = new MLContext();
// Load model & create prediction engine
string modelPath = @"C:\Users\AppData\Local\Temp\MLVSTools\ML.test1ML\ML.test1ML.Model\MLModel.zip";
ITransformer mlModel = mlContext.Model.Load(modelPath, out var modelInputSchema);
var predEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(mlModel);
return predEngine;
}
}위 두개의 클래스를 이용하면 DB에서 바로 데이터를 가져와서 알고리즘도 입맛대로 골라서 학습시키고 예측값을 가져올 수 있다.
아래 포스트에서 연동해서 생각하도록 하자.
728x90
반응형